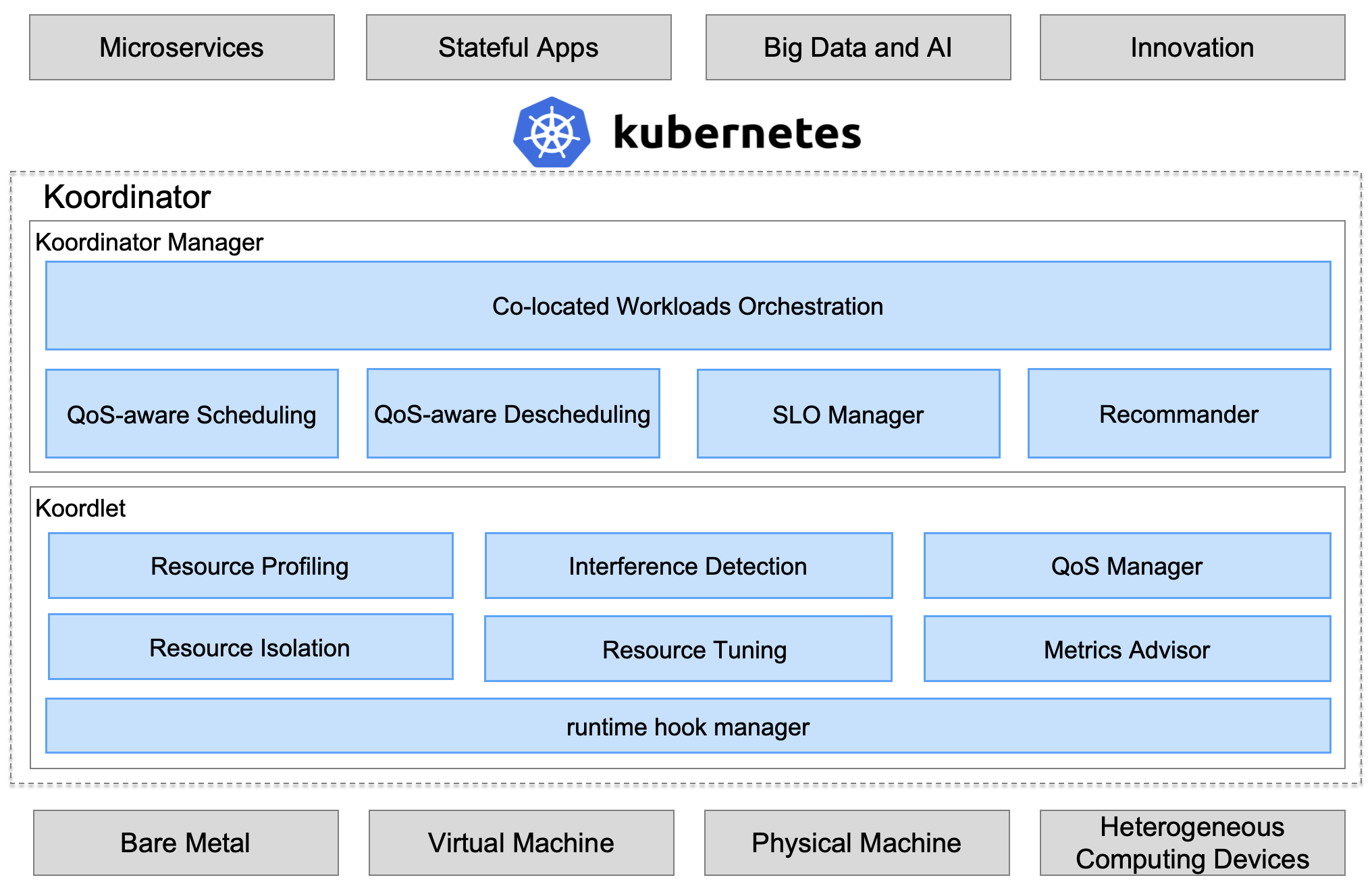
概况 Koordinator 是阿里开源的基于 Kubernetes 支持多工作负载混合部署的调度系统,将弹性的资源配额、高效的 Pod
架构 Koordinator 由两个控制面(Koordinator Scheduler/Koordinator Manager)和一个 DaemonSet 组件(Koordlet)组成。
Koordinator Scheduler Koordinator Scheduler以 Deployment 的形式部署,用于增强 Kubernetes 在混部场景下的资源调度能力,包括:
更多的场景支持,包括弹性配额调度、资源超卖(resource overcommitment)、资源预留(resource reservation)、Gang 调度、异构资源调度。
更好的性能,包括动态索引优化、等价 class 调度、随机算法优化。
更安全的 descheduling,包括工作负载感知、确定性的 pod 迁移、细粒度的流量控制和变更审计支持。
Koordinator Manager Koordinator Manager 以 Deployment 的形式部署,通常由两个实例组成,一个 leader 实例和一个 backup 实例。Koordinator Manager
目前,提供了三个组件:
Colocation Profile,用于支持混部而不需要修改工作负载。用户只需要在集群中做少量的配置,原来的工作负载就可以在混部模式下运行,通过
SLO 控制器,用于资源超卖(resource overcommitment)管理,根据节点混部时的运行状态,动态调整集群的超发(overcommit)
Recommender(即将推出),它使用 histograms 来统计和预测工作负载的资源使用细节,用来预估工作负载的峰值资源需求,从而支持更好地分散热点,提高混部的效率。此外,资源
Koordlet Koordlet 以 DaemonSet 的形式部署在 Kubernetes 集群中,用于支持混部场景下的资源超卖(resource overcommitment)、干扰检测、QoS
在Koordlet内部,它主要包括以下模块:
资源 Profiling,估算 Pod 资源的实际使用情况,回收已分配但未使用的资源,用于低优先级 Pod 的 overcommit。
资源隔离,为不同类型的 Pod 设置资源隔离参数,避免低优先级的 Pod 影响高优先级 Pod 的稳定性和性能。
干扰检测,对于运行中的 Pod,动态检测资源争夺,包括 CPU 调度、内存分配延迟、网络、磁盘 IO 延迟等。
QoS 管理器,根据资源剖析、干扰检测结果和 SLO 配置,动态调整混部节点的水位,抑制影响服务质量的 Pod。
资源调优,针对混部场景进行容器资源调优,优化容器的 CPU Throttle、OOM 等,提高服务运行质量。
QoS QoS 用于表达节点上 Pod 的运行质量,如获取资源的方式、获取资源的比例、QoS 保障策略等。
定义
QoS
特点
说明
SYSTEM
系统进程,资源受限
对于 DaemonSets 等系统服务,虽然需要保证系统服务的延迟,但也需要限制节点上这些系统服务容器的资源使用,以确保其不占用过多的资源
LSE(Latency Sensitive Exclusive)
保留资源并组织同 QoS 的 pod 共享资源
很少使用,常见于中间件类应用,一般在独立的资源池中使用
LSR(Latency Sensitive Reserved)
预留资源以获得更好的确定性
类似于社区的 Guaranteed,CPU 核被绑定
LS(Latency Sensitive)
共享资源,对突发流量有更好的弹性
微服务工作负载的典型QoS级别,实现更好的资源弹性和更灵活的资源调整能力
BE(Best Effort)
共享不包括 LSE 的资源,资源运行质量有限,甚至在极端情况下被杀死
批量作业的典型 QoS 水平,在一定时期内稳定的计算吞吐量,低成本资源
Koordinator QoS与 Kubernetes QoS 的对比 从定义部分可以看出,Koordinator 的 QoS 比 Kubernetes 的 QoS 更复杂,因为在混部场景下,我们需要对延迟敏感的工作负载的 QoS
Koordinator 和 Kubernetes QoS 之间是有对应关系的:
Koordinator QoS
Kubernetes QoS
SYSTEM
—
LSE
Guaranteed
LSR
Guaranteed
LS
Guaranteed/Burstable
BE
BestEffort
Koordlet 根据 Pod 的优先级和 QoS 定义,触发相应的资源隔离和 QoS 保障。
安装 按照官网文档安装 koordinator
1 2 3 4 5 6 7 8 $ helm repo add koordinator-sh https://koordinator-sh.github.io/charts/ $ helm repo update $ helm install koordinator koordinator-sh/koordinator --version 1.1.1
安装完成之后在 koordinator-system namespace 查看部署的Pod,包含四个组件 koord-descheduler、koord-scheduler、koord-manager 和
1 2 3 4 5 6 7 8 9 10 11 $ kubectl get pod -n koordinator-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES koord-descheduler-667c77dcdc-647nh 1/1 Running 0 65m 10.244.2.65 node2 <none> <none> koord-descheduler-667c77dcdc-95752 1/1 Running 0 65m 10.244.1.56 tv3-tcbase-ciliumtest-01 <none> <none> koord-manager-dcb687d77-cml9w 1/1 Running 0 65m 10.244.0.35 master <none> <none> koord-manager-dcb687d77-lkqvd 1/1 Running 0 65m 10.244.2.63 node2 <none> <none> koord-scheduler-9c68ff967-bb4tn 1/1 Running 0 65m 10.244.1.55 tv3-tcbase-ciliumtest-01 <none> <none> koord-scheduler-9c68ff967-mkr4b 1/1 Running 0 65m 10.244.2.64 node2 <none> <none> koordlet-4fc8t 1/1 Running 0 40m 10.177.43.174 node2 <none> <none> koordlet-drkx9 1/1 Running 0 41m 10.177.43.173 tv3-tcbase-ciliumtest-01 <none> <none> koordlet-hbhps 1/1 Running 0 40m 10.177.43.172 master <none> <none>
然后部署 官网的Demo ,将 spark job 通过
在部署 spark job 之前,要创建 cluster-colocation 的配置,对 spark job 开启离线调度,这样 koordinator 才能无侵入的将BE的配置注入到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiVersion: v1 kind: Namespace metadata: name: spark-demo labels: koordinator.sh/enable-colocation: "true" --- apiVersion: config.koordinator.sh/v1alpha1 kind: ClusterColocationProfile metadata: name: spark-demo spec: namespaceSelector: matchLabels: koordinator.sh/enable-colocation: "true" selector: matchLabels: sparkoperator.k8s.io/launched-by-spark-operator: "true" qosClass: BE priorityClassName: koord-batch koordinatorPriority: 1000 schedulerName: koord-scheduler
查看部署的 spark job 的 pod
1 2 3 4 5 6 7 8 $ kubectl get pod -n spark-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES spark-tc-complex-driver 1/1 Running 0 3m31s 10.244.0.42 master <none> <none> sparktc-5dd11a8727158b95-exec-1 1/1 Running 0 3m16s 10.244.2.70 node2 <none> <none> sparktc-5dd11a8727158b95-exec-2 1/1 Running 0 3m16s 10.244.1.63 tv3-tcbase-ciliumtest-01 <none> <none> sparktc-5dd11a8727158b95-exec-3 1/1 Running 0 3m16s 10.244.0.43 master <none> <none> sparktc-5dd11a8727158b95-exec-4 1/1 Running 0 3m16s 10.244.2.71 node2 <none> <none>
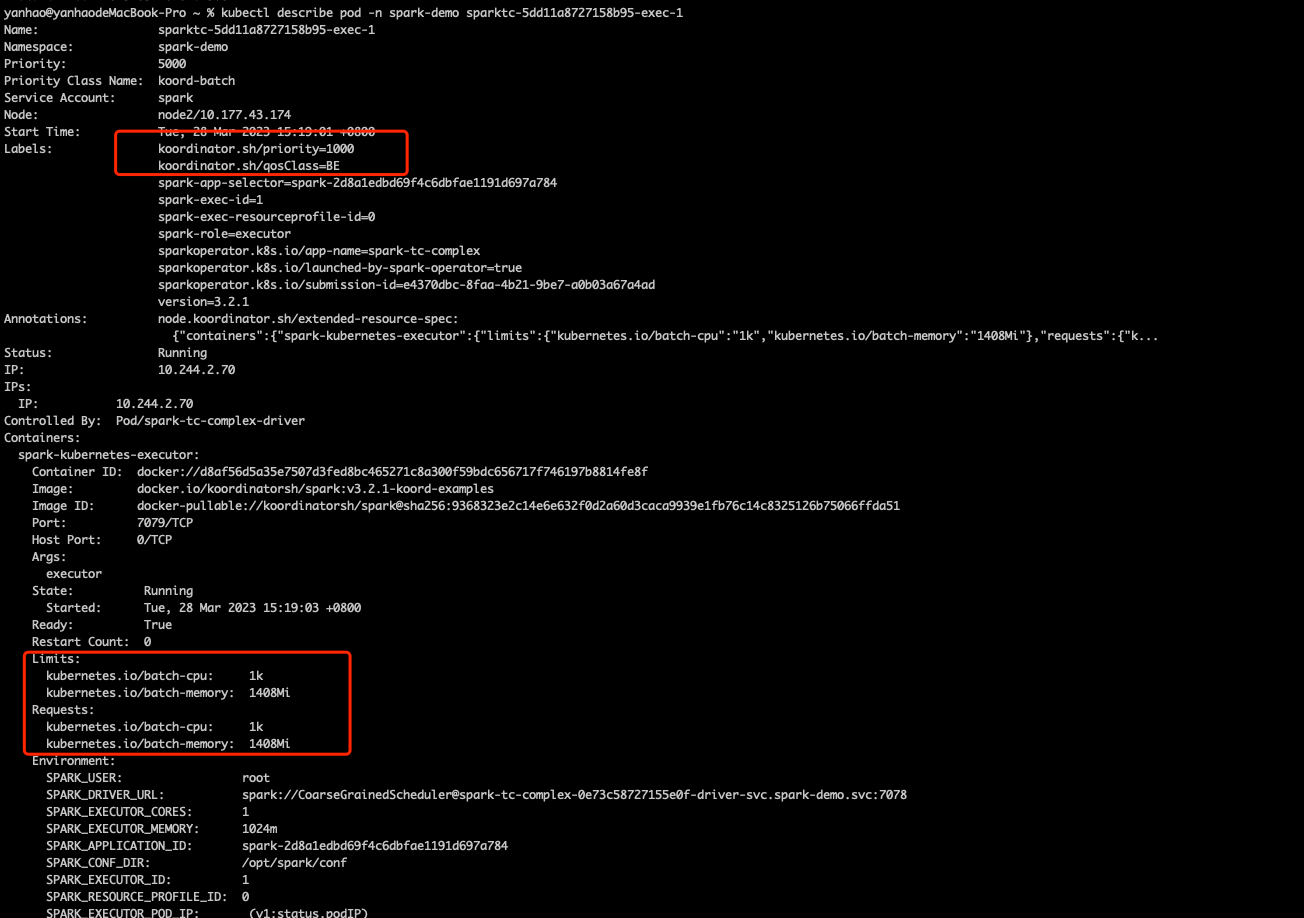
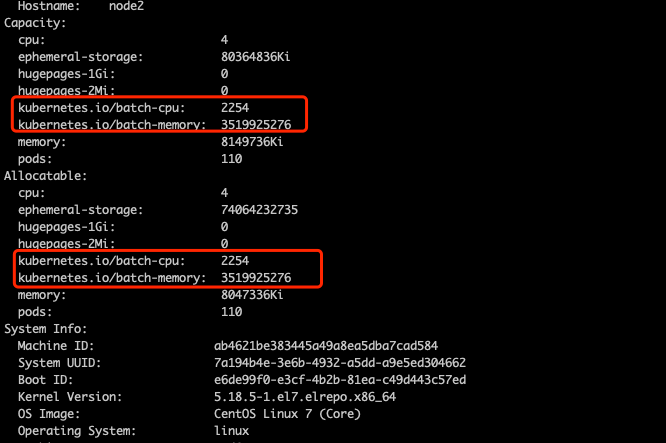
选择一个 Pod 查看详细信息,可以看到 Pod 的 label 上的 koordinator.sh/qosClass 的类型已经设置为 BE 类型,而且 Pod 所申请的
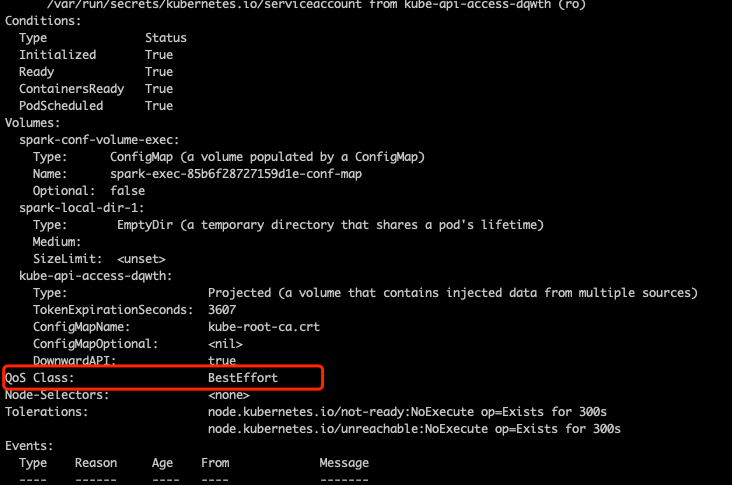
而 Kubernetes 原始 cpu、mem 均没有设置按照 Kubernetes qos 的定义 cpu、mem 均没有设置值的 qos 是 BestEffort,验证一下确实是
而 BestEffort 类型的 Pod cgroup 的 cpu.cfs_quota_us 和 memory.limit_in_bytes 都是 -1 代表对 cpu、mem 没有限制。去宿主机验证一下由
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@tv3-tcbase-ciliumtest-01 ~] 9da4a872be71 39a102ae3f0a "/opt/entrypoint.sh …" 21 minutes ago Up 21 minutes k8s_spark-kubernetes-executor_sparktc-5dd11a8727158b95-exec-2_spark-demo_73d62416-3bc4-4a1a-8834-d84acba71462_0 282da221f3ca registry.aliyuncs.com/google_containers/pause:3.6 "/pause" 21 minutes ago Up 21 minutes k8s_POD_sparktc-5dd11a8727158b95-exec-2_spark-demo_73d62416-3bc4-4a1a-8834-d84acba71462_0 [root@tv3-tcbase-ciliumtest-01 ~] "CgroupnsMode" : "host" , "Cgroup" : "" , "CgroupParent" : "kubepods-besteffort-pod73d62416_3bc4_4a1a_8834_d84acba71462.slice" , "DeviceCgroupRules" : null, [root@tv3-tcbase-ciliumtest-01 kubepods-besteffort-pod73d62416_3bc4_4a1a_8834_d84acba71462.slice] 100000 [root@tv3-tcbase-ciliumtest-01 kubepods-besteffort-pod73d62416_3bc4_4a1a_8834_d84acba71462.slice] 100000 [root@tv3-tcbase-ciliumtest-01 kubepods-besteffort-pod73d62416_3bc4_4a1a_8834_d84acba71462.slice] 1476395008 [root@tv3-tcbase-ciliumtest-01 kubepods-besteffort-pod73d62416_3bc4_4a1a_8834_d84acba71462.slice] 1476395008
查看之后发现即使是 BestEffort ,cpu、mem 均做了限制而去都是 Pod 上 kubernetes.io/batch-cpu、kubernetes.io/batch-memory
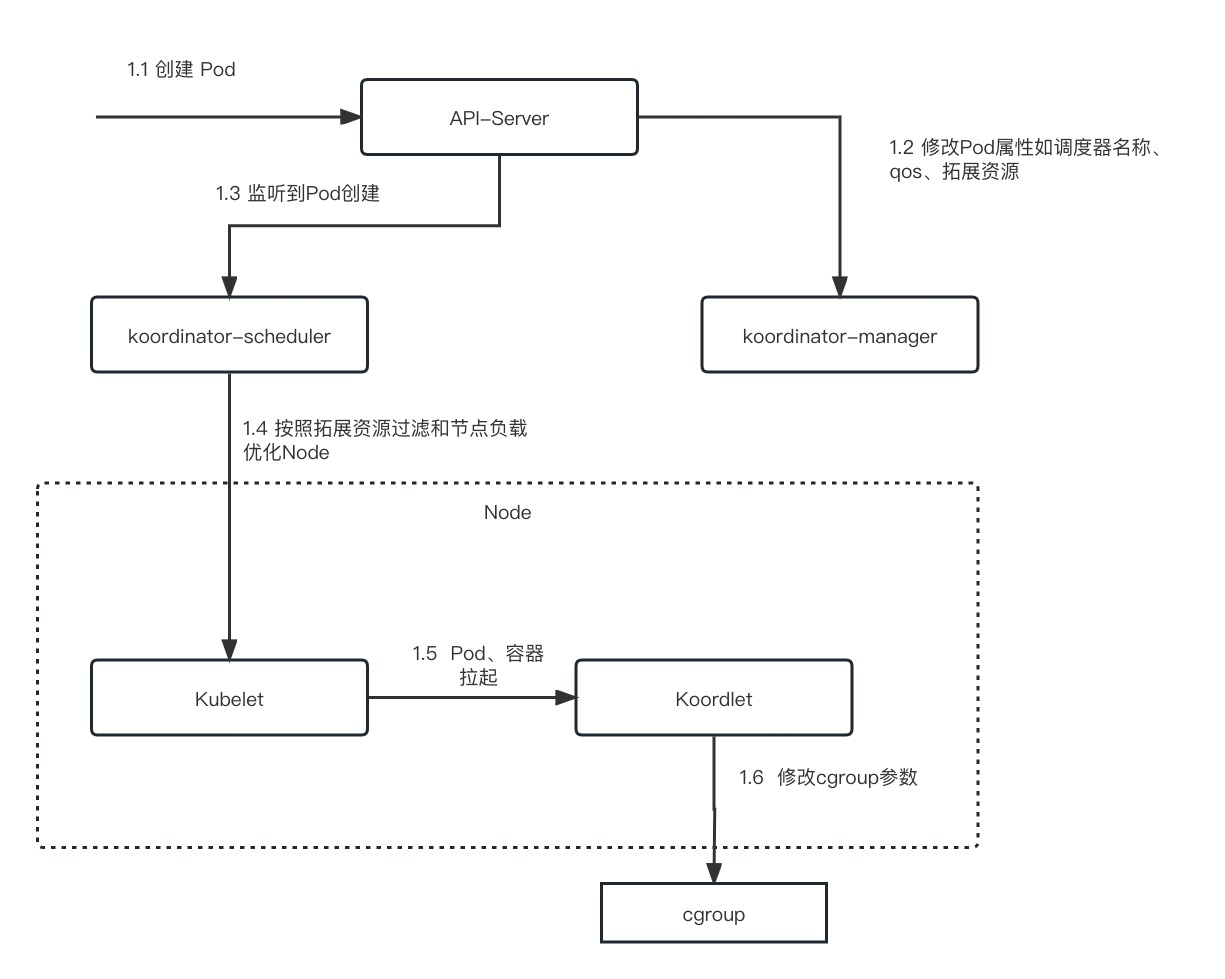
分析 上诉 spark job Pod 的创建和调度流程如下:
调用 api-server 创建 Pod;
通过 webhook koordinator-manager 组件修改 Pod 的调度器名称、qos和拓展资源等信息;
koordinator-scheduler 监听到 Pod 的创建按照内部插件过滤、优选 Node,重要的插件有按照拓展资源过滤和节点真实负载调度;
Kubelet 在节点上拉起容器,Koordlet 监听到 Pod 和容器的创建,根据拓展资源的信息修改 cgroup 的参数;
这是离线 Pod 极简的调度流程,接下来将对 koordinator 每个组件的源码进行分析。由于 koordinator
koordlet koordlet 是所有组件中最复杂的,最重要的几个功能点在于指标和设备信息采集、资源隔离设置、资源压制与驱逐。这对操作系统了解要比较了解,因为要涉及到一些隔离参数的设置包括
启动 启动流程比较简单,创建各种组件并启动起来,下面是对各个组件详细的介绍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func NewDaemon (config *config.Configuration) error ) {... metricCache, err := metriccache.NewMetricCache(config.MetricCacheConf) collectorService := metricsadvisor.NewMetricAdvisor(config.CollectorConf, statesInformer, metricCache) resManagerService := resmanager.NewResManager(config.ResManagerConf, scheme, kubeClient, crdClient, nodeName, statesInformer, metricCache, int64 (config.CollectorConf.CollectResUsedIntervalSeconds)) qosManager := qosmanager.NewQosManager(config.QosManagerConf, scheme, kubeClient, nodeName, statesInformer, metricCache) runtimeHook, err := runtimehooks.NewRuntimeHook(statesInformer, config.RuntimeHookConf) d := &daemon{ metricAdvisor: collectorService, statesInformer: statesInformer, metricCache: metricCache, resManager: resManagerService, qosManager: qosManager, runtimeHook: runtimeHook, } return d, nil } func (d *daemon) chan struct {}) {go func () if err := d.metricCache.Run(stopCh); err != nil {klog.Fatalf("Unable to run the metric cache: " , err) } }() ... go func () if err := d.runtimeHook.Run(stopCh); err != nil {klog.Fatalf("Unable to run the runtimeHook: " , err) } }() }
collectorService 这个服务功能有以下几点
收集 Pod 的 cpu、mem 使用情况;
收集 Node 的 cpu、mem 使用情况;
收集 Node CPU 信息,包括 CPU 核数、socket、l3、node 等信息;
其他设备的信息比如 gpu;
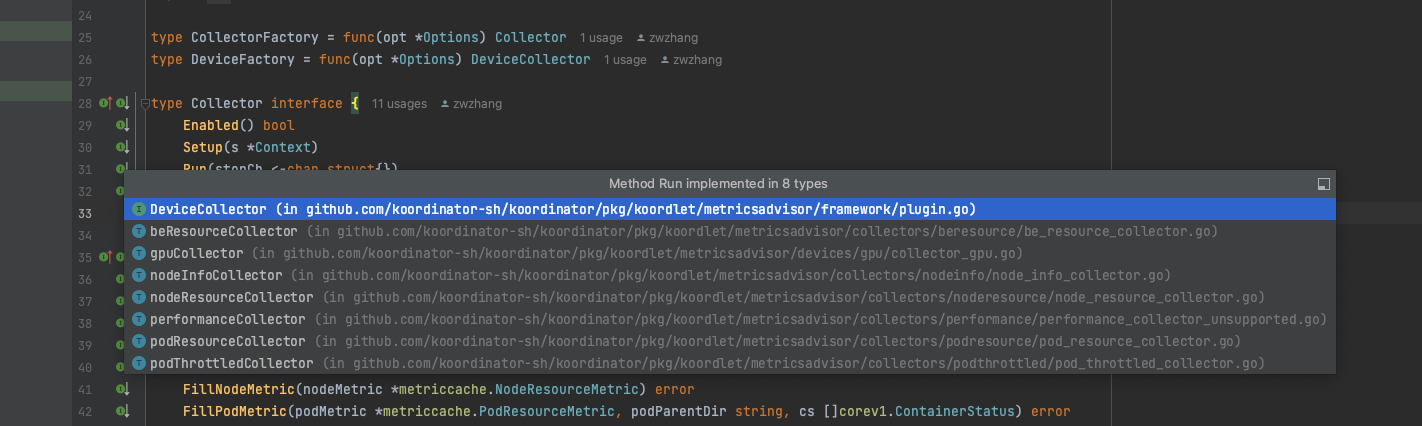
Pod指标收集流程 接下来看一下 Pod 指标的收集流程,代码在 pod_resource_collector 中。
1 2 3 4 5 6 7 8 9 10 func (p *podResourceCollector) chan struct {}) {devicesSynced := func () bool { return framework.DeviceCollectorsStarted(p.deviceCollectors)} if !cache.WaitForCacheSync(stopCh, p.statesInformer.HasSynced, devicesSynced) {klog.Fatalf("timed out waiting for states informer caches to sync" ) } go wait.Until(p.collectPodResUsed, p.collectInterval, stopCh)}
Run 方法将启动一个定时任务,定时收集 Pod 指标,收集周期默认为 1 s,下面是简化的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 func (p *podResourceCollector) podMetas := p.statesInformer.GetAllPods() for _, meta := range podMetas {pod := meta.Pod uid := string (pod.UID) collectTime := time.Now() podCgroupDir := meta.CgroupDir currentCPUUsage, err0 := p.cgroupReader.ReadCPUAcctUsage(podCgroupDir) memStat, err1 := p.cgroupReader.ReadMemoryStat(podCgroupDir) } podMetric := metriccache.PodResourceMetric{ PodUID: uid, CPUUsed: metriccache.CPUMetric{ CPUUsed: *resource.NewMilliQuantity(int64 (cpuUsageValue*1000 ), resource.DecimalSI), }, MemoryUsed: metriccache.MemoryMetric{ MemoryWithoutCache: *resource.NewQuantity(memUsageValue, resource.BinarySI), }, } if err := p.metricDB.InsertPodResourceMetric(collectTime, &podMetric); err != nil {klog.Errorf("insert pod %s/%s, uid %s resource metric failed, metric %v, err %v" , pod.Namespace, pod.Name, uid, podMetric, err) } p.collectContainerResUsed(meta) } }
Node 指标的收集和 Pod 的大同小异就不一一分析了。
指标上报流程 收集到 Pod 和 Node 的资源使用情况之后需要通过 crd 上报给 api-server ,以便于在调度和拓展资源计算中使用。下面分析一下指标的上报流程。
指标上报到的代码在 states_nodemetric.go 中,为了逻辑统一就和指标采集放在一起了。
1 2 3 4 5 6 7 8 9 10 11 12 func (r *nodeMetricInformer) chan struct {}) {reportInterval := r.getNodeMetricReportInterval() for {select {case <-stopCh:return case <-time.After(reportInterval):r.sync() reportInterval = r.getNodeMetricReportInterval() } } }
首先也是一个定时任务上报指标,默认上报周期是 60S。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 func (r *nodeMetricInformer) ... nodeMetricInfo, podMetricInfo := r.collectMetric() if nodeMetricInfo == nil {klog.Warningf("node metric is not ready, skip this round." ) return } newStatus := &slov1alpha1.NodeMetricStatus{ UpdateTime: &metav1.Time{Time: time.Now()}, NodeMetric: nodeMetricInfo, PodsMetric: podMetricInfo, } retErr := retry.RetryOnConflict(retry.DefaultBackoff, func () error { nodeMetric, err := r.nodeMetricLister.Get(r.nodeName) if errors.IsNotFound(err) {klog.Warningf("nodeMetric %v not found, skip" , r.nodeName) return nil } else if err != nil { klog.Warningf("failed to get %s nodeMetric: %v" , r.nodeName, err) return err} err = r.statusUpdater.updateStatus(nodeMetric, newStatus) return err}) ... }
NodeMetric 数据格式,Node 数据包含平均值和 5m、10m、30m 各个百分位的值,百分位的数据用于调度中,而 Pod 仅有平均值,最后还有
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 apiVersion: slo.koordinator.sh/v1alpha1 kind: NodeMetric metadata: creationTimestamp: "2023-03-28T05:59:52Z" generation: 1 name: node2 resourceVersion: "2408353" uid: 8d995bec-859c-4fd2-b15d-785a4daaa508 spec: metricCollectPolicy: aggregateDurationSeconds: 300 reportIntervalSeconds: 60 status: nodeMetric: aggregatedNodeUsages: - duration: 5m0s usage: p50: resources: cpu: 1158m memory: 1915232Ki p90: resources: cpu: 1218m memory: 1920740Ki p95: resources: cpu: 1238m memory: 1921776Ki p99: resources: cpu: 1611m memory: 1925908Ki - duration: 10m0s usage: p50: resources: cpu: 1158m memory: 1914720Ki p90: resources: cpu: 1218m memory: 1921128Ki p95: resources: cpu: 1257m memory: 1922352Ki p99: resources: cpu: 1611m memory: 1925460Ki - duration: 30m0s usage: p50: resources: cpu: 1158m memory: 1913280Ki p90: resources: cpu: 1209m memory: 1921168Ki p95: resources: cpu: 1248m memory: 1922624Ki p99: resources: cpu: 1697m memory: 1927884Ki nodeUsage: resources: cpu: 1174m memory: "1960085340" podsMetric: - name: metrics-server-79b99c4d99-92xj9 namespace: kube-system podUsage: resources: cpu: 2m memory: "30705615" updateTime: "2023-03-29T07:29:21Z"
resManagerService 这个服务功能在于对资源的管理,基本流程都是通过定时任务按照配置定期设置操作系统参数,包括以下功能:
cpu 压制
cpu burst
cpu、mem 驱逐
l3 隔离
有些功能需要操作系统或硬件的支持比如 cpu burst 和 l3 隔离,这里就分析一下 cpu 压制和驱逐的流程。
cpu 压制 CPU 压制的目的是在节点负载增加的时候可以抑制 BE 类型的工作负载,确保节点上容器的稳定性,和在负载减少时增加 BE 类型工作负载的资源配额。
如上图所示
CPU Threshold 代表节点 CPU 使用率的阈值,Pod (LS).Usage 表示 LS pod 的 CPU 使用率。 CPU Restriction for BE 限制表示 BE pod 的 CPU 使用率。BE pod 可以使用的 CPU 资源量是根据 LS pod 的 CPU 使用率增减来调整的。计算公式如下:
1 suppress(BE) := node.Total * SLOPercent - pod(LS).Used - system.Used
当 Pod (LS).Usage 的使用率上升,BE 可使用的 CPU 资源资源将会减少便会抑制 BE Pod 的CPU资源,上图通过绑核的方式减少 BE Pod 所能使用的 cpu 核数从而达到抑制 CPU 的目的。
代码入口在 cpu_suppress.go 文件,以下为代码的主要流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func (r *CPUSuppress) nodeSLO := r.resmanager.getNodeSLOCopy() .... suppressCPUQuantity := r.calculateBESuppressCPU(node, nodeMetric, podMetrics, podMetas, *nodeSLO.Spec.ResourceUsedThresholdWithBE.CPUSuppressThresholdPercent) ... nodeCPUInfo, err := r.resmanager.metricCache.GetNodeCPUInfo(&metriccache.QueryParam{}) if nodeSLO.Spec.ResourceUsedThresholdWithBE.CPUSuppressPolicy == slov1alpha1.CPUCfsQuotaPolicy { r.adjustByCfsQuota(suppressCPUQuantity, node) r.suppressPolicyStatuses[string (slov1alpha1.CPUCfsQuotaPolicy)] = policyUsing r.recoverCPUSetIfNeed(koordletutil.ContainerCgroupPathRelativeDepth) } else { r.adjustByCPUSet(suppressCPUQuantity, nodeCPUInfo) r.suppressPolicyStatuses[string (slov1alpha1.CPUSetPolicy)] = policyUsing r.recoverCFSQuotaIfNeed() } }
驱逐 驱逐包括 cpu 驱逐和 mem 驱逐,基本流程都是一样的,这里就分析 cpu 驱逐的流程。
代码流程在 cpu_evict 文件中。
1 2 3 4 5 6 7 8 9 10 11 12 func (c *CPUEvictor) ... nodeSLO := c.resmanager.getNodeSLOCopy() ... node := c.resmanager.statesInformer.GetNode() cpuCapacity := node.Status.Capacity.Cpu().Value() ... c.evictByResourceSatisfaction(node, thresholdConfig, windowSeconds) klog.V(5 ).Info("cpu evict process finished." ) }
进入到 evictByResourceSatisfaction 方法,可以看到驱逐实例有三个主要的步骤
1 2 3 4 5 6 7 8 9 10 11 12 13 func (c *CPUEvictor) int64 ) { if !isSatisfactionConfigValid(thresholdConfig) { return } currentBECPU, milliRelease := c.calculateMilliRelease(thresholdConfig, windowSeconds) if milliRelease > 0 { bePodInfos := c.getPodEvictInfoAndSort(currentBECPU) c.killAndEvictBEPodsRelease(node, bePodInfos, milliRelease) } }
根据监控数据和配置的阈值计算出需要驱逐的 cpu 数量是多少;
获取 BE 类型的 Pod 并按照优先级和 cpu 使用率进行排序;
执行实际驱逐 Pod 的动作,并在驱逐之前先 kill 容器,直到驱逐 Pod 的 cpu使用率达到 milliRelease;
runtimeHook runtimeHook 顾名思义是在 Pod 创建的时候注册的一系列钩子,用于BE Pod、容器 cgroup 的设置和一些系统参数创建。此服务主要做以下几个功能
根据拓展资源 kubernetes.io/batch-cpu、kubernetes.io/batch-memory 设置 Pod 和容器的资源限制;
对 Pod CPU 进行精细化的编排,例如 CPU 绑定策略、CPU 独占策略、NUMA 拓扑对齐策略和NUMA 拓扑信息等;
对 GPU 的管理;
Pod 生命周期变更的 Hook 触发有两个地方,一个是通过 RuntimeProxy 触发,还有就是 koordlet 定时同步 Pod 信息和 watch cgroup 文件目录监听 Pod 和容器的创建进行触发。
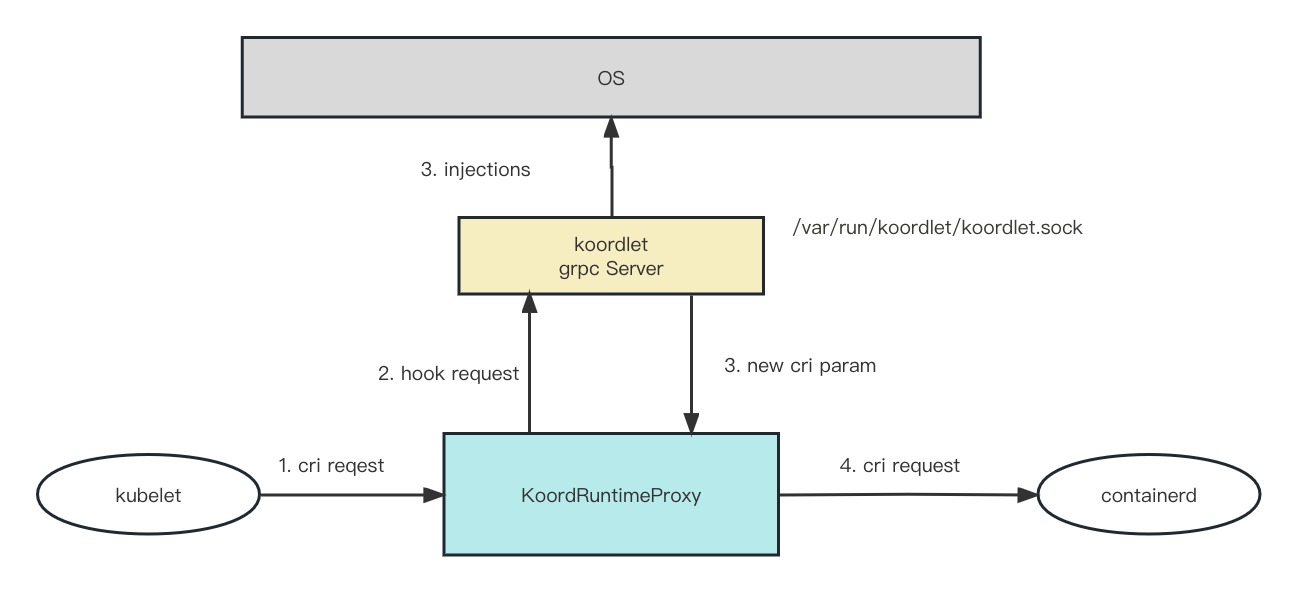
RuntimeProxy KoordRuntimeProxy 充当 Kubelet 和 Containerd 之间的代理( Dockershim 场景下是 Dockerd ),它用于拦截 CRI 请求,并应用一些资源管理策略, 如混合工作负载编排场景下按实例优先级设置不同的 cgroup 参数,针对最新的 Linux 内核、CPU 架构应用新的隔离策略等。
RuntimeProxy 这个组件会作为 kubelet 的 CRI 允许,在 Pod 和容器创建的时候 kubelet 会请求 cri,RuntimeProxy 将会拦截这些请求,触发注册到 RuntimeProxy 上的插件(通过 gRPC 调用)获取到插件修改之后的 cri 请求参数继续请求后端 containerd 组件。
RuntimeProxy 有以下几个 Hook
1 2 3 4 5 6 7 8 9 const ( PreRunPodSandbox RuntimeHookType = "PreRunPodSandbox" PostStopPodSandbox RuntimeHookType = "PostStopPodSandbox" PreCreateContainer RuntimeHookType = "PreCreateContainer" PreStartContainer RuntimeHookType = "PreStartContainer" PostStartContainer RuntimeHookType = "PostStartContainer" PreUpdateContainerResources RuntimeHookType = "PreUpdateContainerResources" PostStopContainer RuntimeHookType = "PostStopContainer" )
kubelet 请求 cri 创建容器;
runtimeproxy 拦截请求触发注册好的插件,通过 gRPC 请求;
koordlet 通过触发的 Hook ,有些需要修改 OS 参数,有些需要改变 cri 请求参数;
runtimeproxy 通过插件返回结果构建新的 cri 请求参数,请求 containerd;
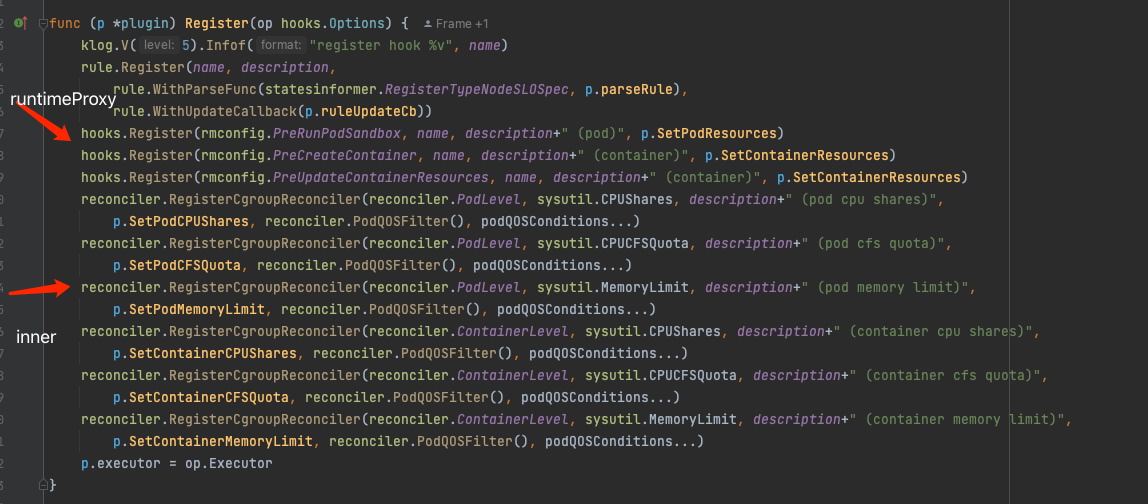
Watch And Sync 在插件注册的时候可以寻找两种类型一个是通过 runtimeProxy 触发的还有是通过 koordlet 内部触发,这里就分析 koordlet 是怎么监听 Pod 的变更的。
reconciler.RegisterCgroupReconciler() 是将注册的 func 通过一个 map 存起来,这里找一下在那里触发 map 里的 func 的,发现在 reconciler.go 的 reconcilePodCgroup 方法中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func (c *reconciler) chan struct {}) { for { select { case <-c.podUpdated: podsMeta := c.getPodsMeta() for _, podMeta := range podsMeta { for _, r := range globalCgroupReconcilers.podLevel { .... } case <-stopCh: klog.V(1 ).Infof("stop reconcile pod cgroup" ) return } } }
可以看到这个方法通过 chan podUpdated 阻塞获取 pod 更新事件,再跟一下是在哪里触发的 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func (c *reconciler) interface {}, podsMeta []*statesinformer.PodMeta) { c.podsMutex.Lock() defer c.podsMutex.Unlock() c.podsMeta = podsMeta if len (c.podUpdated) == 0 { c.podUpdated <- struct {}{} } } func NewReconciler (op Options) r := &reconciler{ podUpdated: make (chan struct {}, 1 ), executor: op.Executor, } op.StatesInformer.RegisterCallbacks(statesinformer.RegisterTypeAllPods, "runtime-hooks-reconciler" , "Reconcile cgroup files if pod updated" , r.podRefreshCallback) return r }
又注册了一个 Pod 更新回调的方法,再跟一下发现触发的代码在 states_pods.go 的 syncPods 中,而 syncPods 触发如下,通过定时任务和事件触发。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 func (s *podsInformer) chan struct {}) { timer := time.NewTimer(duration) defer timer.Stop() s.syncPods() for { select { case <-s.podCreated: if rateLimiter.Allow() { s.syncPods() } else { klog.V(4 ).Infof("new pod created, but sync rate limiter is not allowed" ) } case <-timer.C: timer.Reset(duration) s.syncPods() case <-stopCh: klog.Infof("sync kubelet loop is exited" ) return } } }
再找一下事件触发是在哪里,最后发现在 pleg 文件中,通过 watch cgroup 下文件的删除和创建事件触发的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (p *pleg) chan struct {}) error { qosClasses := []corev1.PodQOSClass{corev1.PodQOSGuaranteed, corev1.PodQOSBurstable, corev1.PodQOSBestEffort} for _, qosClass := range qosClasses { cgroupPath := getWatchCgroupPath(p.cgroupRootPath, qosClass) err := p.podWatcher.AddWatch(cgroupPath) } .... go p.runEventHandler(stopCh) for { select { case evt := <-p.podWatcher.Event(): switch TypeOf(evt) { case DirCreated: basename := filepath.Base(evt.Name) podID, err := koordletutil.ParsePodID(basename) if err != nil { klog.Infof("skip %v added event which is not a pod" , evt.Name) continue } p.events <- newPodEvent(podID, podAdded) ... } }
有上诉代码的跟踪发现 koordlet 内部 Pod 生命周期的 Hook 是通过定时任务和 watch cgroup 文件触发的。
slo-controller 这个组件的作用在于根据配置和上报的监控指标计算出 BE 资源的可使用量。
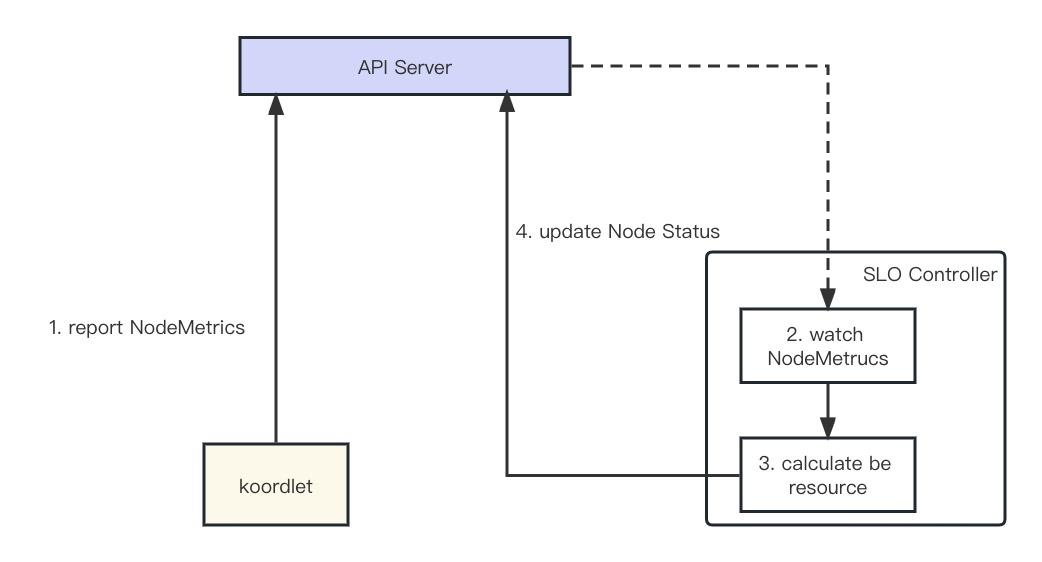
koordlet 通过 CRD NodeMetric 的形式每分钟上报 Pod、Node 的 cpu、mem 指标,之前分析的流程;
SLO Controller 监听到 NodeMetric 发生变动,开始更新 BE 之前;
根据公式 Node(BE).Alloc = Node.Total - Node.Reserved - System.Used - Pod(LS).Used 计算出新的 BE 资源;
1 2 3 batchAllocatableByUsage := quotav1.Max(quotav1.Subtract(quotav1.Subtract(quotav1.Subtract( nodeAllocatable, nodeReserve), systemUsed), podLSUsed), util.NewZeroResourceList())
将计算出新的 BE 之前更新到 Node Status 中。
scheduler scheduler 通过 scheduling-framework 机制对 Pod 的调度进行拓展,包括以下插件
LoadAwareScheduling:按照节点实际负载进行调度,平衡集群资源使用率;
NodeNUMAResource: 按照节点 CPU 的 NUMA 结构进行调度;
Reservation: 资源预留,在创建 Pod 之前提前为 Pod 预留资源;
BatchResourceFit:将 BE 资源不足的节点过滤出去;
ElasticQuota:弹性配额,管理共享集群中不同用户资源使用的能力;
DeviceShare: 可以根据拓展设备进行调度,如 gpu;
Coscheduling: 批量调度,all-or-nothing;
总结 Koordinator 框架结构比较清晰,都是通过 Kubernetes 拓展点实现的功能,对 Kubernetes 无侵入性,从代码质量和功能来说都是比较优秀的,是一个值得学习的框架。