
Raft 算法的一个重要特性便是易于理解和实现。随着对Raft 的深入了解和参考一些工程上的实现,发现实现一个稳定、高性能的Raft算法其实并不简单,许多论文中一笔带过的优化在实现中都是需要考虑的。本文做 Raft 实现的相关优化做一个总结,只是个人学习的一个记录并不能覆盖所有的情况。
预投票
在了解预投票之前先看下面一个场景。
下图描述的情况为:在节点 A、B、C 三个服务组成 raft 集群,节点 A 在term 1当选为 leader。某一时刻发生网络分区,将网络划分为 [A,B]、[C],节点 C 将会接受不到 leader A 的请求。节点 C 心跳超时之后发起选举请求 ,由于网络分区的存在,选举也会超时然后触发下一轮的选举。
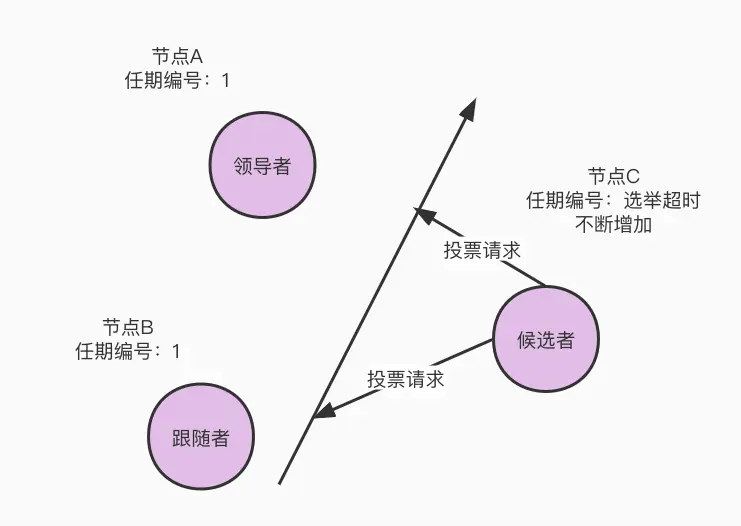
假如后面网络恢复了,节点 C 能够将投票请求发送给 A、B 节点,A节点发现 C 的term比自身高将会降级成 follower并更新自身的 term。这将会导致集群leader不稳定并会抬高整个集群的 term。
为了避免上诉情况的发生,可以采用预投票的方法处理。所谓预投票就是发送起请求请求之前先发起预投票(pre-vote),如果没有得到半数以上节点的反馈将不会发起投票选举。
但是预投票能处理所有的破坏集群稳定性的情况吗?以下举了两个例子
上面描述发生网络分区的情况,节点 C 与节点A、B 都不能通讯,使用预投票可以处理这种场景,但是如果节点 C 与A不能通讯与 B 能够通讯呢?也会破坏集群的稳定性。
在发生更改集群配置的情况下,一旦Leader创建了 Cnew 条目,不在 Cnew 中的服务器将不再接收心跳信号,因此它将超时并开始新的选举,这将导致当前的领导者转为跟随者状态。
所以为了保障集群的稳定性在预投票基础上还可以使用另外一种方式优化,即当服务能够确定集群中 leader 是有效存在的将会拒绝投票请求也不会更新自身的任期。对于 follower 如果在选举超时的最小周期内接受到了 leader 心跳便认为是集群中leader是有效的,拒绝选举请求,对于 leader 通过追踪和follower的心跳状态来确定自己是否有效。
读优化
读操作不会改变状态机,很自然的优化想法是读操作不生成 Log,但如果直接读取状态机的数据并不能保证线性读,即在一个写请求完成之后对于之后的读请求都是可见的。既要保证读请求的线性一致还需要满足读请求的高性能,主要有两种优化方式 ReadIndex 和 LeaseRead。
ReadIndex
ReadIndex 操作并不会生成日志,因此会减少磁盘和网络 IO。Leader 执行 ReadIndex基本流程如下:
记录当前的 commit index,存入局部变量 ReadIndex;
向 follower 发起一次心跳,如果大多数节点回复了,那就能确定现在仍然是 leader;
等待状态机至少应用到 readIndex 记录的 log;
执行读请求,将结果返回给 client;
LeaseRead
LeaseRead 与 ReadIndex 相似,不过比 ReadIndex 少去了向 follower 发送心跳确认自己 leader,减少了一步网络 IO。基本的思路是一旦集群的大多数成员都认可了领导者的心跳,取一个比Election Timeout 小的租期,在租期内集群中不会发生选举,leader 不会发生改变,可以跳过上诉第 2 步。LeaseRead 的形式依赖本地时钟,如果发生时钟漂移可能返回过期的信息。
另外ReadIndex 和 LeaseRead 都可以在 follower 上执行,分担 leader 的读压力。基本流程如下:
follower 接受到读请求;
follower 请求leader 获取 readindex变量;
等待状态机至少应用到 readIndex 记录的 log;
执行读请求,将结果返回给 client;
No-op日志
在论文 Figure 8 中提到 leader 不能直接提交之前任期的日志,即使日志已经复制到集群大多数节点。leader 只能提交当前任期的日志,通过日志匹配的特性间接提交之前任期的日志。
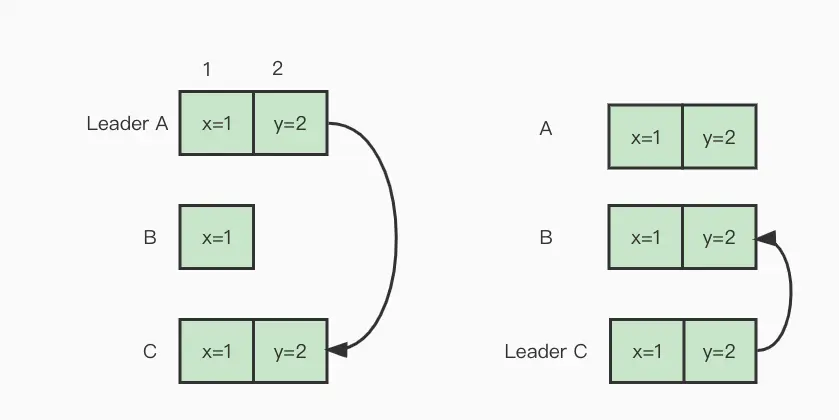
此特性会带来一些比较诡异的现象,如上图的描述:
集群中有三个服务 A、B、C,其中服务 A 担任任期编号 1 的leader;
客户端发起一个写入请求,leader 处理客户端请求在 index 为2的地方生成一条日志;
leader 将 index 为 2 的日志复制服务C,日志还没来得及提交服务便挂掉了;
服务 C 获取B、C选票成为 任期 2 的 leader,将 index 为 2 的日志复制到了服务B,由于日志安全限制不能提交 index 为 2 的日志;
客户端由于服务 A 长时间未响应请求超时,假设客户端有重试逻辑,先查询请求确认写入的数据是否存在,由于之前写入的日志未提交,客户端不会查询出上一次的写入结果,将重新写入,服务端便会存在重复的数据。
此问题可以用no-op 日志解决,所谓no-op 日志是只有 index 和 term 的日志。在 leader 选举成功之后提交一条 no-op 日志,通过 no-op 日志间接提交之前任期的日志。
当然 no-op 日志还不止解决这个问题,在集群变更的时候 no-op 日志也有重要作用,具体的可以看 Raft 成员变更的工程实践 的Raft单步成员变更的问题部分。
写入优化
日志的可以简单分为以下流程:
leader 接受到请求,生成日志持久化到本地;
leader 并发的将日志复制给 follower;
follower 将日志持久化到本地;
集群中半数节点持久化日志之后,apply 日志,leader响应客户端;
可以看到写入一条日志涉及到的磁盘和网络IO都是比较多的,想要达到写入的高性能可以针对写入流程做以下优化:
Batch:如果每条日志都单独持久化和复制给 follower 成本太高了,可以将日志批量持久化和复制;
Pipeline:leader 发送给 follower 日志数据通过 next index 维护,这种情况下 leader 不需要等待客户端的响应结果即可复制下一批日志,因此可以采用 pipeline的形式进行日志复制。即使发生日志不匹配需要回退 next index 的情况 pipeline 也可以处理;
Asynchronous:可以将leader 将日志持久化到本地和日志复制并行处理,只要大多数节点将日志持久化之后便可以将日志 commit;
总结
本文列举了一些 raft 常见的优化形式,Batch和Asynchronous都是常见的优化手段,但如何在Batch的时候不影响响应时间是需要思考的,具体的细节还需要看工程项目是怎么做的。关于 Pipeline 如果使用 gRPC 做为服务直接的通讯使用 Stream 就能实现。